On my team, we do two different things in our Continuous Integration setup: build/functional tests, and performance tests. Build tests simply test whether a project builds, and, if the project provides a functional test suite, that the tests pass. We do a lot of MySQL/MariaDB testing this way. The other type of testing we do is performance tests: we build a project and then run a set of benchmarks against it. Python is a good example here.
Build tests want as much grunt as possible. Performance tests, on the other hand, want a stable, isolated environment. Initially, we set up Jenkins so that performance and build tests never ran at the same time. Builds would get the entire machine, and performance tests would never have to share with anyone.
This, while simple and effective, has some downsides. In POWER land, our machines are quite beefy. For example, one of the boxes I use - an S822L - has 4 sockets, each with 4 cores. At SMT-8 (an 8 way split of each core) that gives us 4 x 4 x 8 = 128 threads. It seems wasteful to lock this entire machine - all 128 threads - just so as to isolate a single-threaded test.1
So, can we partition our machine so that we can be running two different sorts of processes in a sufficiently isolated way?
What counts as 'sufficiently isolated'? Well, my performance tests are CPU bound, so I want CPU isolation. I also want memory, and in particular memory bandwith to be isolated. I don't particularly care about IO isolation as my tests aren't IO heavy. Lastly, I have a couple of tests that are very multithreaded, so I'd like to have enough of a machine for those test results to be interesting.
For CPU isolation we have CPU affinity. We can also do something similar with memory. On a POWER8 system, memory is connected to individual P8s, not to some central point. This is a 'Non-Uniform Memory Architecture' (NUMA) setup: the directly attached memory will be very fast for a processor to access, and memory attached to other processors will be slower to access. An accessible guide (with very helpful diagrams!) is the relevant RedBook (PDF), chapter 2.
We could achieve the isolation we want by dividing up CPUs and NUMA nodes between the competing workloads. Fortunately, all of the hardware NUMA information is plumbed nicely into Linux. Each P8 socket gets a corresponding NUMA node. lscpu will tell you what CPUs correspond to which NUMA nodes (although what it calls a CPU we would call a hardware thread). If you install numactl, you can use numactl -H to get even more details.
In our case, the relevant lscpu output is thus:
NUMA node0 CPU(s): 0-31
NUMA node1 CPU(s): 96-127
NUMA node16 CPU(s): 32-63
NUMA node17 CPU(s): 64-95
Now all we have to do is find some way to tell Linux to restrict a group of processes to a particular NUMA node and the corresponding CPUs. How? Enter control groups, or cgroups for short. Processes can be put into a cgroup, and then a cgroup controller can control the resouces allocated to the cgroup. Cgroups are hierarchical, and there are controllers for a number of different ways you could control a group of processes. Most helpfully for us, there's one called cpuset, which can control CPU affinity, and restrict memory allocation to a NUMA node.
We then just have to get the processes into the relevant cgroup. Fortunately, Docker is incredibly helpful for this!2 Docker containers are put in the docker cgroup. Each container gets it's own cgroup under the docker cgroup, and fortunately Docker deals well with the somewhat broken state of cpuset inheritance.3 So it suffices to create a cpuset cgroup for docker, and allocate some resources to it, and Docker will do the rest. Here we'll allocate the last 3 sockets and NUMA nodes to Docker containers:
cgcreate -g cpuset:docker
echo 32-127 > /sys/fs/cgroup/cpuset/docker/cpuset.cpus
echo 1,16-17 > /sys/fs/cgroup/cpuset/docker/cpuset.mems
echo 1 > /sys/fs/cgroup/cpuset/docker/cpuset.mem_hardwall
mem_hardwall prevents memory allocations under docker from spilling over into the one remaining NUMA node.
So, does this work? I created a container with sysbench and then ran the following:
root@0d3f339d4181:/# sysbench --test=cpu --num-threads=128 --max-requests=10000000 run
Now I've asked for 128 threads, but the cgroup only has CPUs/hwthreads 32-127 allocated. So If I run htop, I shouldn't see any load on CPUs 0-31. What do I actually see?
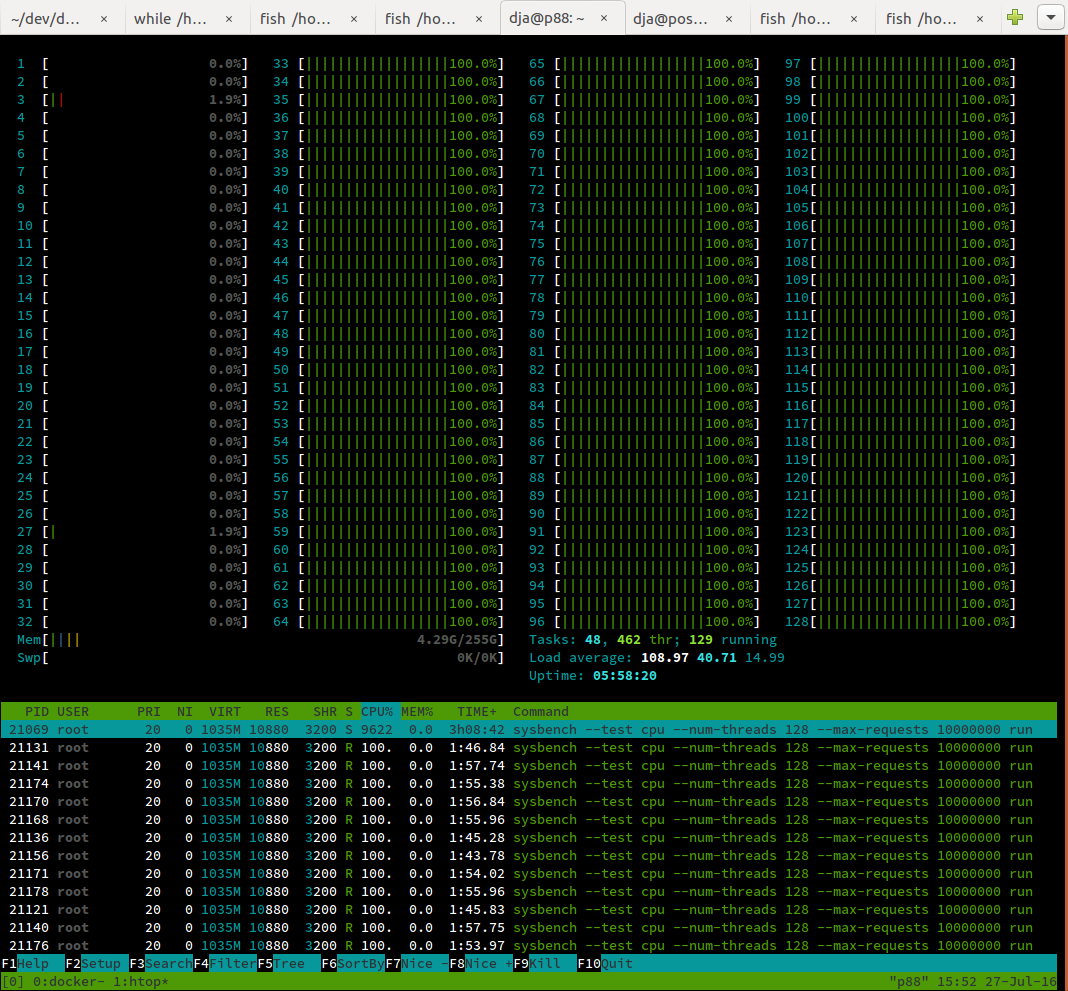
It works! Now, we create a cgroup for performance tests using the first socket and NUMA node:
cgcreate -g cpuset:perf-cgroup
echo 0-31 > /sys/fs/cgroup/cpuset/perf-cgroup/cpuset.cpus
echo 0 > /sys/fs/cgroup/cpuset/perf-cgroup/cpuset.mems
echo 1 > /sys/fs/cgroup/cpuset/perf-cgroup/cpuset.mem_hardwall
Docker conveniently lets us put new containers under a different cgroup, which means we can simply do:
dja@p88 ~> docker run -it --rm --cgroup-parent=/perf-cgroup/ ppc64le/ubuntu bash
root@b037049f94de:/# # ... install sysbench
root@b037049f94de:/# sysbench --test=cpu --num-threads=128 --max-requests=10000000 run
And the result?
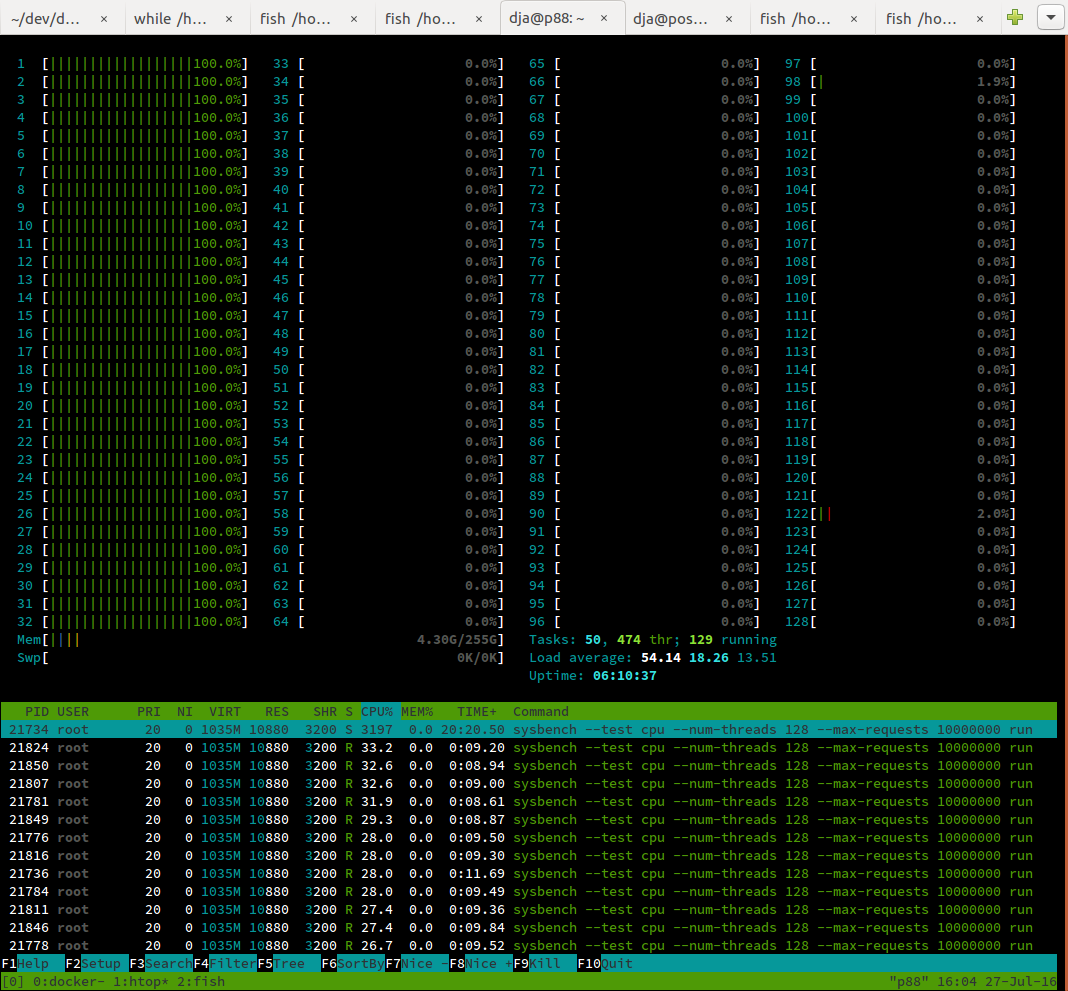
It works! My benchmark results also suggest this is sufficient isolation, and the rest of the team is happy to have more build resources to play with.
There are some boring loose ends to tie up: if a build job does anything outside of docker (like clone a git repo), that doesn't come under the docker cgroup, and we have to interact with systemd. Because systemd doesn't know about cpuset, this is quite fiddly. We also want this in a systemd unit so it runs on start up, and we want some code to tear it down. But I'll spare you the gory details.
In summary, cgroups are surprisingly powerful and simple to work with, especially in conjunction with Docker and NUMA on Power!
-
It gets worse! Before the performance test starts, all the running build jobs must drain. If we have 8 Jenkins executors running on the box, and a performance test job is the next in the queue, we have to wait for 8 running jobs to clear. If they all started at different times and have different runtimes, we will inevitably spend a fair chunk of time with the machine at less than full utilisation while we're waiting. ↩
-
At least, on Ubuntu 16.04. I haven't tested if this is true anywhere else. ↩
-
I hear this is getting better. It is also why systemd hasn't done cpuset inheritance yet. ↩