Recently a set of 8 vulnerabilities were disclosed for the grub bootloader. I found 2 of them (CVE-2021-20225 and CVE-2021-20233), and contributed a number of other fixes for crashing bugs which we don't believe are exploitable. I found them by applying fuzz testing to grub. Here's how.
This is a multi-part series: I think it will end up being 4 posts. I'm hoping to cover:
- Part 1: getting started with fuzzing grub
- Part 2 (this post): going faster by doing lots more work
- Part 3: fuzzing filesystems and more
- Part 4: potential next steps and avenues for further work
We've been looking at fuzzing grub-emu, which is basically most parts of grub
built into a standard userspace program. This includes all the script parsing
logic, fonts, graphics, partition tables, filesystems and so on - just not
platform specific driver code or the ability to actually load and boot a kernel.
Previously, we talked about some issues building grub with AFL++'s instrumentation:
:::text
./configure --with-platform=emu --disable-grub-emu-sdl CC=$AFL_PATH/afl-cc
...
checking whether target compiler is working... no
configure: error: cannot compile for the target
It also doesn't work with afl-gcc.
We tried to trick configure:
:::shell
./configure --with-platform=emu --disable-grub-emu-sdl CC=clang CXX=clang++
make CC="$AFL_PATH/afl-cc"
Sadly, things still break:
:::text
/usr/bin/ld: disk.module:(.bss+0x20): multiple definition of `__afl_global_area_ptr'; kernel.exec:(.bss+0xe078): first defined here
/usr/bin/ld: regexp.module:(.bss+0x70): multiple definition of `__afl_global_area_ptr'; kernel.exec:(.bss+0xe078): first defined here
/usr/bin/ld: blocklist.module:(.bss+0x28): multiple definition of `__afl_global_area_ptr'; kernel.exec:(.bss+0xe078): first defined here
The problem is the module linkage that I talked about in part 1.
There is a link stage of sorts for the kernel (kernel.exec) and each module
(e.g. disk.module), so some AFL support code gets linked into each of
those. Then there's another link stage for grub-emu itself, which also tries
to bring in the same support code. The linker doesn't like the symbols being in
multiple places, which is fair enough.
There are (at least) 3 ways you could solve this. I'm going to call them the hard way, and the ugly way and the easy way.
The hard way: messing with makefiles
We've been looking at fuzzing grub-emu. Building grub-emu links
kernel.exec and almost every .module file that grub produces into the
final binary. Maybe we could avoid our duplicate symbol problems entirely by
changing how we build things?
I didn't do this in my early work because, to be honest, I don't like working
with build systems and I'm not especially good at it. grub's build system is
based on autotools but is even more quirky than usual: rather than just having a
Makefile.am, we have Makefile.core.def which is used along with other things
to generate Makefile.am. It's a pretty cool system for making modules, but
it's not my idea of fun to work with.
But, for the sake of completeness, I tried again.
It gets unpleasant quickly. The generated grub-core/Makefile.core.am adds each module to platform_PROGRAMS, and then each is built with LDFLAGS_MODULE = $(LDFLAGS_PLATFORM) -nostdlib $(TARGET_LDFLAGS_OLDMAGIC) -Wl,-r,-d.
Basically, in the makefile this ends up being (e.g.):
:::make
tar.module$(EXEEXT): $(tar_module_OBJECTS) $(tar_module_DEPENDENCIES) $(EXTRA_tar_module_DEPENDENCIES)
@rm -f tar.module$(EXEEXT)
$(AM_V_CCLD)$(tar_module_LINK) $(tar_module_OBJECTS) $(tar_module_LDADD) $(LIBS)
Ideally I don't want them to be linked at all; there's no benefit if they're just going to be linked again.
You can't just collect the sources and build them into grub-emu - they all
have to built with different CFLAGS! So instead I spent some hours messing
around with the build system. Given some changes to the python script that
converts the Makefile.*.def files into Makefile.am files, plus some other
bits and pieces, we can build grub-emu by linking the object files rather than
the more-processed modules.
The build dies immediately after linking grub-emu in other components, and it
requires a bit of manual intervention to get the right things built in the right
order, but with all of those caveats, it's enough. It works, and you can turn on
things like ASAN, but getting there was hard, unrewarding and unpleasant. Let's
consider alternative ways to solve this problem.
The ugly way: patching AFL
What I did when finding the bugs was to observe that we only wanted AFL to link
in its extra instrumentation at certain points of the build process. So I
patched AFL to add an environment variable AFL_DEFER_LIB - which prevented AFL
adding its own instrumentation library when being called as a linker. I combined
this with the older CFG instrumentation, as the PCGUARD instrumentation brought
in a bunch of symbols from LLVM which I didn't want to also figure out how to
guard.
I then wrapped this in a horrifying script that basically built bits and pieces
of grub with the environment variable on or off, in order to at least get the
userspace tools and grub-emu built. Basically it set AFL_DEFER_LIB when
building all the modules and turned it off when building the userspace tools
and grub-emu.
This worked and it's what I used to find most of my bugs. But I'd probably not recommend it, and I'm not sharing the source: it's extremely fragile and brittle, the hard way is more generally applicable, and the easy way is nicer.
The easy way: adjusting linker flags
After posting part 1 of this series, I had a fascinating twitter DM conversation with @hackerschoice, who pointed me to some new work that had been done in AFL++ between when I started and when I published part 1.
AFL++ now has the ability to dynamically detect some duplicate symbols, allowing
it to support plugins and modules better. This isn't directly applicable because
we link all the modules in at build time, but in the conversation I was pointed
to a linker flag which instructs the linker to ignore the symbol duplication
rather than error out. This provides a significantly simpler way to instrument
grub-emu, avoiding all the issues I'd previously been fighting so hard to
address.
So, with a modern AFL++, and the patch from part 1, you can sort out this entire process like this:
:::shell
./bootstrap
./configure --with-platform=emu CC=clang CXX=clang++ --disable-grub-emu-sdl
make CC=/path/to/afl-clang-fast LDFLAGS="-Wl,--allow-multiple-definition"
Eventually it will error out, but ./grub-core/grub-emu should be successfully
built first.
(Why not just build grub-emu directly? It gets built by grub-core/Makefile,
but depends on a bunch of things made by the top-level makefile and doesn't
express its dependencies well. So you can try to build all the things that you
need separately and then cd grub-core; make ...flags... grub-emu if you want -
but it's way more complicated to do it that way!)
Going extra fast: __AFL_INIT
Now that we can compile with instrumentation, we can use __AFL_INIT. I'll
leave the precise details of how this works to the AFL docs, but in short it
allows us to do a bunch of early setup only once, and just fork the process
after the setup is done.
There's a patch that inserts a call to __AFL_INIT in the grub-emu start path
in my GitHub repo.
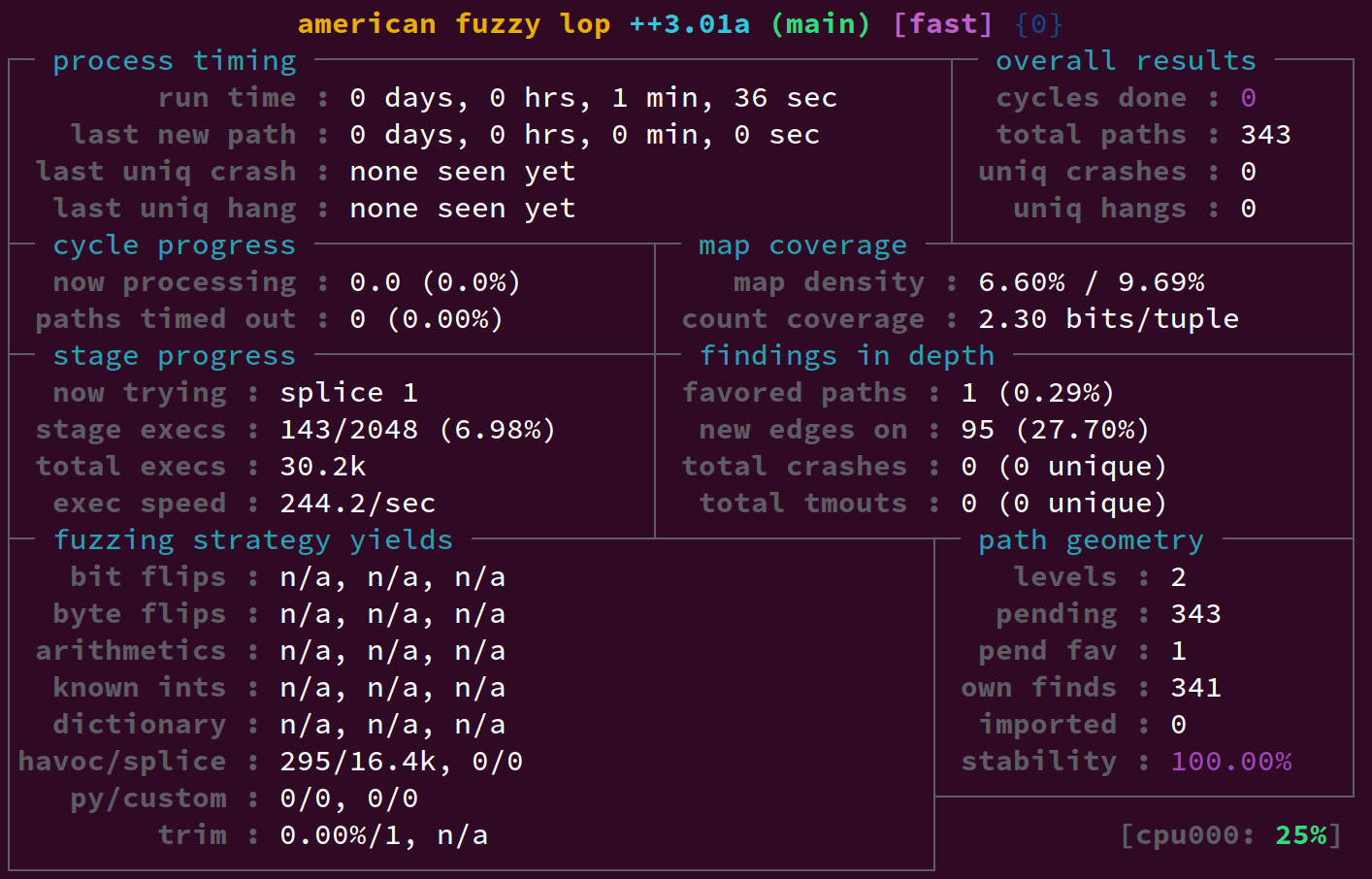
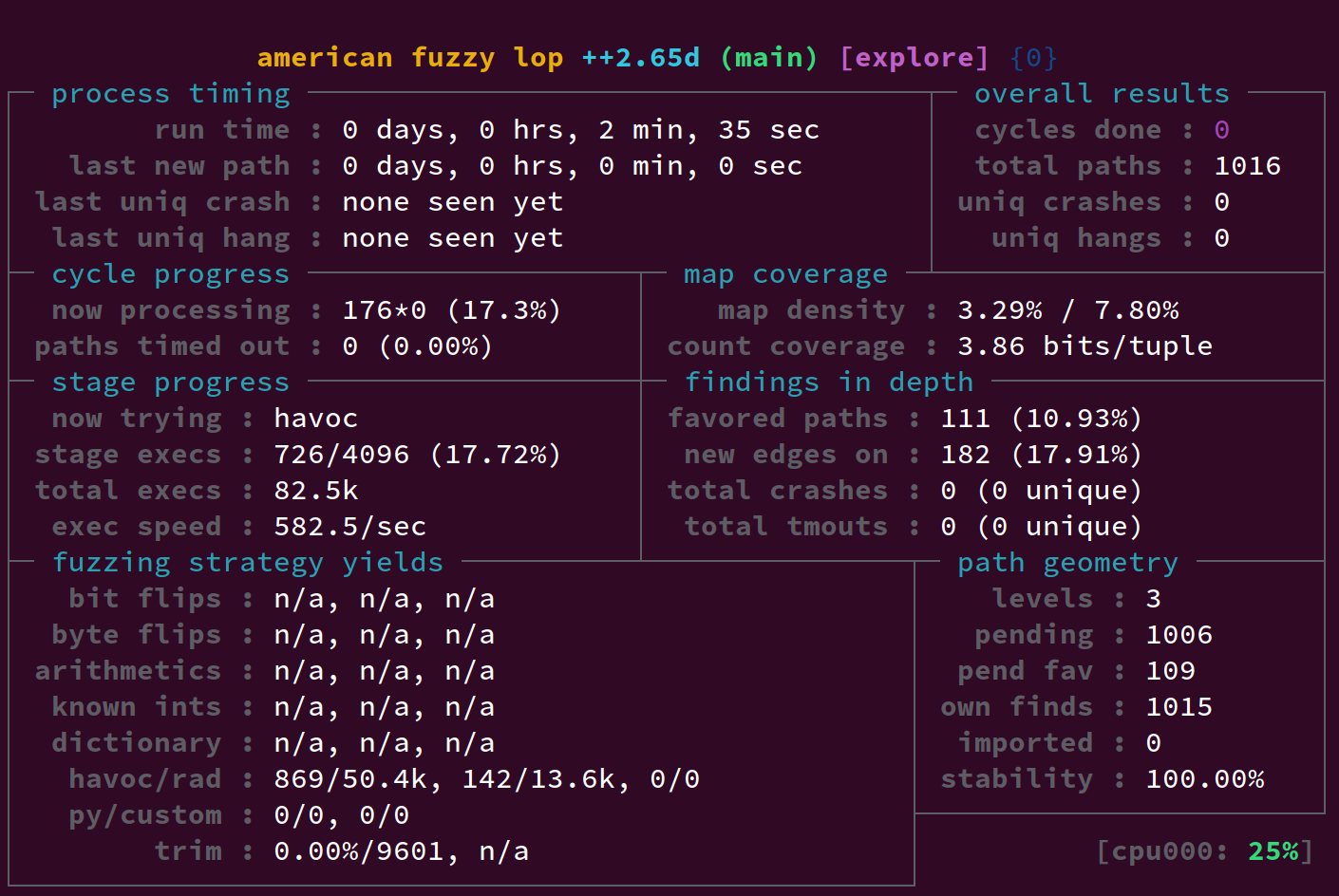
All up, this can lead to a 2x-3x speedup over the figures I saw in part 1. In part 1 we saw around 244 executions per second at this point - now we're over 500:
Finding more bugs with sanitisers
A 'sanitizer' refers to a set of checks inserted by a compiler at build time to detect various runtime issues that might not cause a crash or otherwise be detected. A particularly common and useful sanitizer is ASAN, the AddressSanitizer, which detects out-of-bounds memory accesses, use-after-frees and other assorted memory bugs. Other sanitisers can check for undefined behaviour, uninitialised memory reads or even breaches of control flow integrity.
ASAN is particularly popular for fuzzing. In theory, compiling with AFL++ and
LLVM makes it really easy to compile with ASAN. Setting AFL_USE_ASAN=1 should
be sufficient.
However, in practice, it's quite fragile for grub. I believe I had it all working, and then I upgraded my distro, LLVM and AFL++ versions, and everything stopped working. (It's possible that I hadn't sufficiently cleaned my source tree and I was still building based on the hard way? Who knows.)
I spent quite a while fighting "truncated relocations". ASAN instrumentation was
bloating the binaries, and the size of all the *.module files was over 512MB,
which I suspect was causing the issues. (Without ASAN, it only comes to 35MB.)
I tried afl-clang-lto: I installed lld, rebuilt AFL++, and managed to
segfault the linker while building grub. So I wrote that off. Changing the
instrumentation type to classic didn't help either.
Some googling
suggested GCC's -mmodel, which in Clang seems to be -mcmodel, but
CFLAGS="-mcmodel=large" didn't get me any further either: it's already added
in a few different links.
My default llvm is llvm-12, so I tried building with llvm-9 and llvm-11 in case that helped. Both built a binary, but it would fail to start:
:::text
==375638==AddressSanitizer CHECK failed: /build/llvm-toolchain-9-8fovFY/llvm-toolchain-9-9.0.1/compiler-rt/lib/sanitizer_common/sanitizer_common_libcdep.cc:23 "((SoftRssLimitExceededCallback)) == ((nullptr))" (0x423660, 0x0)
The same happens if I build with llvm-12 and afl-clang, the old-style
instrumentation.
I spun up a Ubuntu 20.04 VM and build there with LLVM 10 and the latest stable AFL++. That didn't work either.
I had much better luck using GCC's and GCC's ASAN implementation, either with
the old-school afl-gcc or the newer GCC plugin-based afl-gcc-fast. (I have
some hypotheses around shared library vs static library ASAN, but having spent
way more work time on this than was reasonable, I was disinclined to debug it
further.) Here's what worked for me:
:::shell
./configure --with-platform=emu --disable-grub-emu-sdl
# the ASAN option is required because one of the tools leaks memory and
# that breaks the generation of documentation.
# -Wno-nested-extern makes __AFL_INIT work on gcc
ASAN_OPTIONS=detect_leaks=0 AFL_USE_ASAN=1 make CC=/path/to/afl-gcc-fast LDFLAGS="-Wl,--allow-multiple-definition" CFLAGS="-Wno-nested-extern"
GCC doesn't support as many sanitisers as LLVM, but happily it does support ASAN. AFL++'s GCC plugin mode should get us most of the speed we would get from LLVM, and indeed the speed - even with ASAN - is quite acceptable.
If you persist, you should be able to find some more bugs: for example there's a very boring global array out-of-bounds read when parsing config files.
That's all for part 2. In part 3 we'll look at fuzzing filesystems and more. Hopefully there will be a quicker turnaround between part 2 and part 3 than there was between part 1 and part 2!