Here we are again - back in 2016 I wrote an article on using Atom for kernel development, but I didn't stay using it for too long, instead moving back to Emacs. Atom had too many shortcomings - it had that distinctive Electron feel, which is a problem for a text editor - you need it to be snappy. On top of that, vim support was mediocre at best, and even as a vim scrub I would find myself trying to do things that weren't implemented.
So in the meantime I switched to spacemacs, which is a very well integrated "vim in Emacs" experience, with a lot of opinionated (but good) defaults. spacemacs was pretty good to me but had some issues - disturbingly long startup times, mediocre completions and go-to-definitions, and integrating any module into spacemacs that wasn't already integrated was a big pain.
After that I switched to Doom Emacs, which is like spacemacs but faster and closer to Emacs itself. It's very user configurable but much less user friendly, and I didn't really change much as my elisp-fu is practically non-existent. I was decently happy with this, but there were still some issues, some of which are just inherent to Emacs itself - like no actually usable inbuilt terminal, despite having (at least) four of them.
Anyway, since 2016 when I used Atom, Visual Studio Code (henceforth referred to as Code) came along and ate its lunch, using the framework (Electron) that was created for Atom. I did try it years ago, but I was very turned off by its Microsoft-ness, it seeming lack of distinguishing features from Atom, and it didn't feel like a native editor at all. Since it's massively grown in popularity since then, I decided I'd give it a try.
Vim emulation
First things first for me is getting a vim mode going, and Code has a pretty good one of those. The key feature for me is that there's Neovim integration for Ex-commands, filling a lot of shortcomings that come with most attempts at vim emulation. In any case, everything I've tried to do that I'd do in vim (or Emacs) has worked, and there are a ton of options and things to tinker with. Obviously it's not going to do as much as you could do with Vimscript, but it's definitely not bad.
Theming and UI customisation
As far as the editor goes - it's good. A ton of different themes, you can change the colour of pretty much everything in the config file or in the UI, including icons for the sidebar. There's a huge sore point though, you can't customise the interface outside the editor pretty much at all. There's an extension for loading custom CSS, but it's out of the way, finnicky, and if I wanted to write CSS I wouldn't have become a kernel developer.
Extensibility
Extensibility is definitely a strong point, the ecosystem of extensions is good. All the language extensions I've tried have been very fully featured with a ton of different options, integration into language-specific linters and build tools. This is probably Code's strongest feature - the breadth of the extension ecosystem and the level of quality found within.
Kernel development
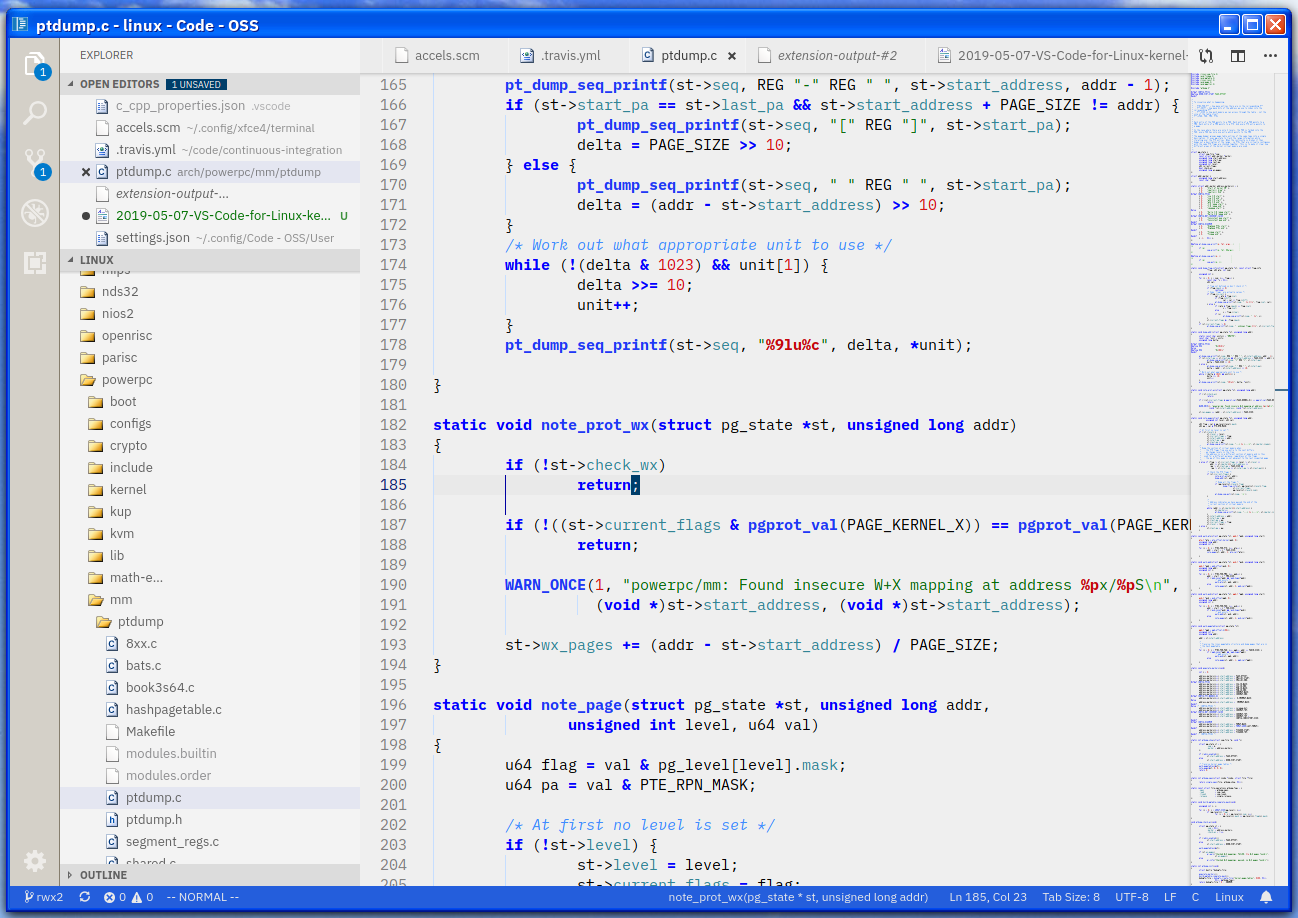
Okay, let's get into the main thing that matters - how well does the thing actually edit code. The kernel is tricky. It's huge, it has its own build system, and in my case I build it with cross compilers for another architecture. Also, y'know, it's all in C and built with make, not exactly great for any kind of IDE integration.
The first thing I did was check out the vscode-linux-kernel project by GitHub user "amezin", which is a great starting point. All you have to do is clone the repo, build your kernel (with a cross compiler works fine too), and run the Python script to generate the compile_commands.json file. Once you've done this, go-to-definition (gd in vim mode) works pretty well. It's not flawless, but it does go cross-file, and will pop up a nice UI if it can't figure out which file you're after.
Code has good built-in git support, so actions like staging files for a commit can be done from within the editor. Ctrl-P lets you quickly navigate to any file with fuzzy-matching (which is impressively fast for a project of this size), and Ctrl-Shift-P will let you search commands, which I've been using for some git stuff.

There are some rough edges, though. Code is set on what so many modern editors are set on, which is the "one window per project" concept - so to get things working the way you want, you would open your kernel source as the current project. This makes it a pain to just open something else to edit, like some script, or checking the value of something in firmware, or chucking something in your bashrc.
Auto-triggering builds on change isn't something that makes a ton of sense for the kernel, and it's not present here. The kernel support in the repo above is decent, but it's not going to get you close to what more modern languages can get you in an editor like this.
Oh, and it has a powerpc assembly extension, but I didn't find it anywhere near as good as the one I "wrote" for Atom (I just took the x86 one and switched the instructions), so I'd rather use the C mode.
Terminal
Code has an actually good inbuilt terminal that uses your login shell. You can bring it up with Ctrl-`. The biggest gripe I have always had with Emacs is that you can never have a shell that you can actually do anything in, whether it's eshell or shell or term or ansi-term, you try to do something in it and it doesn't work or clashes with some Emacs command, and then when you try to do something Emacs-y in there it doesn't work. No such issue is present here, and it's a pleasure to use for things like triggering a remote build or doing some git operation you don't want to do with commands in the editor itself.
Not the most important feature, but I do like not having to alt-tab out and lose focus.
Well...is it good?
Yeah, it is. It has shortcomings, but installing Code and using the repo above to get started is probably the simplest way to get a competent kernel development environment going, with more features than most kernel developers (probably) have in their editors. Code is open source and so are its extensions, and it'd be the first thing I recommend to new developers who aren't already super invested into vim or Emacs, and it's worth a try if you have gripes with your current environment.